- نوسانات در روغن و طلا ممکن است فرصت بیشتری نسبت به خطر داشته باشد
- مهندسی بازار
- توابع بازاریابی
- بازار سهام امروز: معاملات سهام آسیایی عمدتاً پایین تر است
- چگونه می توان به حساب quinx وارد شد؟
- بیت کوین به ریال - نرخ ارز امروز
- چگونه با شاخص های قدرت گاوها و خرس ها معامله کنیم؟
- US20150120381A1 - پیش بینی تبلیغات همپوشانی خرده فروشی با استفاده از یک P-Norm بهینه شده - ثبت اختراعات Google
- راهنمای اصطلاحات رایج فارکس که باید قبل از معامله بدانید
- تجارت سهام: راهنمای مبتدیان

آخرین مطالب
امکانات وب


هدف از این پروژه سنگفرش ، ارزیابی اثربخشی یک رویکرد مبتنی بر خالص عصبی برای تجارت با فرکانس بالا در بازار cryptocurrency بود. پرونده آزمون کتاب سفارش محدودیت قرارداد آتی Deribit را در نظر می گیرد. پنجاه سیگنال به عنوان پیش بینی کننده نتیجه باینری گرفته شد. مدل نهایی یک حافظه کوتاه مدت کوتاه ("LSTM") است که به میزان دقت بیش از 74 رسیده است.
زمینه
مدل های معاملاتی برای موفقیت باید پویا و انعطاف پذیر باشند. مدل ها ممکن است به بسیاری از متغیرها ، اساسی و فنی متکی باشند. در هر صورت ، به خوبی مشخص شده است که یک تاخیر اطلاعاتی برای هر نوع پیش بینی کننده آشکار است-فقط باید اصلاحات مکرر را در شاخص های عملکرد گذشته برای اثبات این ادعا در نظر بگیرید. بنابراین بدیهی است که هر مدل تجاری ارزش نمک خود به داده های سری زمانی متکی است ، و به همین ترتیب ظهور Autoregression است.
اکنون ، انتخاب پیش بینی کننده ها ، چه اساسی و چه فنی ، به نمایش در می آید. ما ادعا می کنیم که در حالی که سیگنال فنی نسبت به همتای اساسی خود سر و صدای بیشتری نشان می دهد ، محمول اصلی چنین سر و صدایی در قالب فعالیت بازار از واردات پیش بینی کننده تر است. این سیالیت بیشتر و محدودیت های زمانی اگزوژن/خود را به سمت قرار دادن مدل خود بر روی شاخص های فنی به تنهایی سوق می دهد.
داده های کتاب سفارش از [آوریل تا مه 2019] از مبادله Deribit با دفاتر اصلی در ارملو ، هلند گرفته شده است. انتخاب مبادله ای کاملاً راحتی نبود بلکه از احتیاط بود. مبادله Deribit به طور گسترده ای در نظر گرفته می شود که کمتر در معرض دستکاری در بازار قرار گرفته است که مبادلات دیگر را به ستوه آورده است.
کتاب سفارش محدود شامل عکسهای عمیق کتاب با سفارش کامل با به روزرسانی های افزایشی ، تجارت با تیک ، علاقه باز ، بودجه ، انحلال و نقل قول ها است. قرارداد دائمی آتی یک محصول مشتق است که شبیه به یک قرارداد سنتی آتی است اما دارای مشخصات متفاوتی برای به حداقل رساندن مبنای ، از جمله پیوند شاخص برای تقلید از بازار نقطه ای مبتنی بر حاشیه و بدون انقضا است.
شاخص Deribit BTC ، به ویژه ، به عنوان میانگین وزن متوسط شش (6) ترکیبات زیر اندازه گیری می شود: Bitstamp ، Gemini ، Bitfinex ، Itbit ، Coinbase و Kraken. سفارشات محدودیت تخفیف 0. 025 ٪ را دریافت می کنند در حالی که سفارشات بازار 0. 05 ٪ است. نمودار زیر بهترین پیشنهاد LOB را از 1 آوریل - 15 آوریل 2019 نشان می دهد.

با این حال ، داده های فرم خام در زمان متناقض است. فواصل تصادفی بین مشاهدات وجود دارد. برای ساختار داده هایی که ممکن است برای تجزیه و تحلیل مناسب باشد ، یک مکانیزم مهندسی Timestamp به کار رفته است که به موجب آن داده ها 20 میلی میلی ثانیه ای انجام می شود که در دسترس باشد و بر اساس آخرین مقدار آن را مجازات می کند. پس از آن ، یک ژنراتور برای تغذیه شبکه عصبی ، جمع آوری داده ها در فواصل یک دقیقه ای به طور متوسط ، جمع بندی یا در غیر این صورت داده های لازم را در صورت لزوم ارائه دهید.
پنجاه (50) شاخص فنی به طور گسترده ای از نظر نوع قابل طبقه بندی هستند و شامل اقدامات (i) ترتیب و بازگشت ، (ب) روند ، (iii) حرکت و (IV) نوسانات است. شاخص های اصلی از کتابخانه تجزیه و تحلیل فنی در پایتون تهیه شده است. با این حال ، شاخص های خاصی برای استفاده از ساختار داده کتاب سفارش محدود ساخته شده اند. نمونه هایی از چنین شاخص ها شامل چندین سفارش لغو ، نوسان ساز (S) و نوسانات فوری است. ادبیات منبع به درخواست نویسندگان در دسترس است.[جزئیاتی که باید اضافه شود و دوباره به عقب برگردید و غیره]
مهندسی ویژگی
مهندسی Timestamp
داده های فرم خام به موقع متناقض است و در فواصل تصادفی از 0 تا 500 میلی ثانیه بین مشاهدات قرار می گیرد. برای ایجاد داده های سازگار ، ما دو روش مختلف را امتحان کردیم.
رویکرد 1: 20 میلی ثانیه به طور سیستماتیک نمونه برداری زمان
اولین رویکرد ما نمونه برداری از داده ها هر 20 میلی ثانیه و ضبط در نزدیکترین نقاط داده بود. اگر یک نقطه داده واحد در این بازه زمانی یافت نشود ، آخرین ردیف شناخته شده داده ها را کپی کرده و آن را تکرار می کنیم. برای مرحله آخر ما ، تفاوت قیمت بین دو فریم زمان را اندازه گیری کردیم ، بنابراین متغیر Y خود را ایجاد می کنیم. این داده ها به صورت ژنراتور ارائه شده است که می تواند مستقیماً در چارچوب شبکه عصبی Keras تغذیه شود.
با این حال ، ما به زودی فهمیدیم که این رویکرد در مدلهای ما عملکرد خوبی نداشته است زیرا اختلاف زمان خیلی کم بود. بیشتر نمونه ها تغییر ناچیز در قیمت داشتند. بنابراین ، مدل ما سعی در پیش بینی تغییر قیمت 0 برای تقریباً در تمام فواصل زمانی داشت. معرفی تعصب در پیش بینی ما.
رویکرد 2: 1 دقیقه تجمیع
در تکرار بعدی پروژه ما ، تصمیم گرفتیم داده ها را در طی یک دقیقه جمع کنیم و بسته به نوع ویژگی ، داده ها را به طور متوسط یا خلاصه می کنیم. با این حال ، این بار ، از آنجا که اندازه مجموعه داده های ما از چند میلیون ردیف برای یک ماه داده به حدود 22000 کاهش یافته است ، ما تصمیم گرفتیم تا مجموعه داده های حاصل را برای راحتی و اهداف آزمایش عمومی در یک پرونده CVS ذخیره کنیم. همچنین ، ما Y خود را از رگرسیون به یک مشکل طبقه بندی تغییر می دهیم. ما به جای تلاش برای پیش بینی مقدار تغییر ، ما فقط در تلاش هستیم تا جهت عملکرد قیمت بیت کوین را پیش بینی کنیم.

مهندسی سیگنال
در اینجا برخی از سیگنالی که برای برنامه خود استفاده می کنیم آورده شده است:
جلد
- شاخص تجمع/توزیع (ADI)
- حجم متعادل (OBV)
- جریان پول Chaikin (CMF)
- شاخص نیرو (FI)
- سهولت حرکت (EOM ، EMV)
- روند قیمت حجم (VPT)
- شاخص حجم منفی (NVI)
نوسان
- نوسانات فوری (IV)
- دامنه واقعی متوسط (ATR)
- گروههای بولینگر (BB)
- کانال کلتنر (KC)
- کانال Donchian (DC)
روند
- حرکت میانگین واگرایی همگرایی (MACD)
- شاخص حرکت جهت متوسط (ADX)
- نشانگر گرداب (VI)
- Trix (Trix)
- شاخص توده (MI)
- شاخص کانال کالا (CCI)
- نوسان ساز قیمت (DPO)
- KST نوسان ساز (KST)
- ichimoku kinkō hyō (ichimoku)
تکانه
- شاخص جریان پول (MFI)
- شاخص قدرت نسبی (RSI)
- شاخص قدرت واقعی (TSI)
- اسیلاتور نهایی (UO)
- نوسان ساز تصادفی (SR)
- ویلیامز ٪ R (WR)
- نوسان ساز عالی (AO)
- میانگین متحرک سازگار Kaufman (KAMA)
دیگران
- لغو سیگنال (CS)
- بازده 15 بازه (15ir)
- بازگشت روزانه (DR)
- بازگشت روزانه گزارش (DLR)
- بازگشت تجمعی (CR)
مدل سازی یادگیری ماشین
مرحله 1: آزمایش مدل های فردی
مدل پایه: طبقه بندی رگرسیون لجستیک
برای مشکلات طبقه بندی ، مدل رگرسیون لجستیک پایه خوبی است که از آن می توانیم عملکرد را مقایسه کنیم. با این حال ، محدودیت هایی دارد:
- این امر مستلزم این است که مشاهدات از یکدیگر مستقل باشند. در یک سری زمانی مداوم یک بازار ، اینگونه نیست.
- در بین متغیرهای X ، چند و همبستگی کمی نیاز دارد. از آنجا که بیشتر سیگنال های ما (یعنی میانگین یا حرکت در حال حرکت) از همان متغیرهای قیمت و حجم محاسبه می شوند - آنها چند قطبی هستند.
- متغیرهای X باید به صورت خطی با شانس ورود به سیستم مرتبط باشند.
از آنجا که مجموعه داده ما بسیاری از این قوانین را از رگرسیون لجستیک می شکند ، ما انتظار نداریم این مدل عملکرد خوبی داشته باشد. پس از انجام تنظیمات HyperParameters با استفاده از بهینه سازی بیزی ، ماتریس سردرگمی برای رگرسیون لجستیک و دقت مدل در زیر نشان داده شده است.
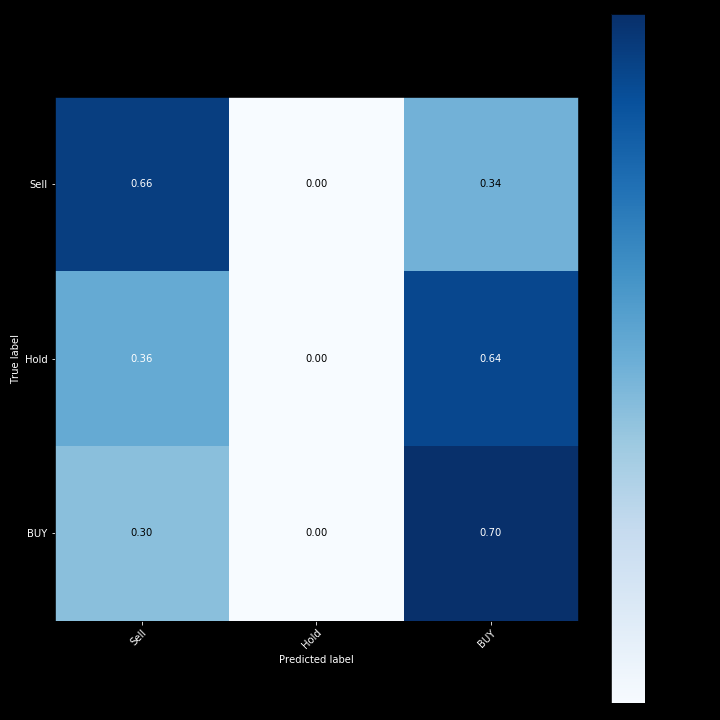
نمره رگرسیون لجستیک دوره زمانی مختلف: 0. 453 - 0. 6496
در زیر برخی از خروجی ها برای مدل رگرسیون لجستیک آورده شده است.
y_pred:
- فروش: 12348
- هیچ چیز: 5 ،
- خرید: 9925
y_actual:
- فروش: 15551
- هیچ چیز: 773
- خرید: 5954
همانطور که از نتیجه می بینید ، مدل LR بسیار متناقض بود و بیشتر اوقات ، کمی بهتر از یک تکلیف تصادفی است. ما تصمیم گرفتیم از یک مدل متفاوت استفاده کنیم که بتواند غیرخطی بودن داده های ما را اداره کند.
مدل پایه پیشرفته: طبقه بندی دستگاه بردار پشتیبانی
الگوریتم بعدی که ما استفاده کردیم SVM ، یک روش طبقه بندی غیر خطی و غیر پارامتری بود. SVM از ترفندهای هسته و مفاهیم حداکثر حاشیه استفاده می کند ، بنابراین در تئوری ، در کارهای غیر خطی و ابعادی بالا عملکرد بسیار بهتری دارد. با این حال ، "ناهار رایگان" در استفاده از SVM وجود ندارد.
مزایای SVM:
- انعطاف پذیری: قادر به قرار دادن تعداد زیادی از اشکال عملکردی.
- قدرت: هیچ فرضیه یا فرضیات ضعیفی در مورد عملکرد اساسی وجود ندارد.
- عملکرد برای مدل پیچیده: می تواند منجر به مدل های عملکرد بالاتر برای پیش بینی شود.
- وقت گیر: یافتن عملکرد مناسب هسته آسان نیست
- آهسته تر: SVM های هسته ای نیاز به محاسبه عملکرد فاصله بین هر نقطه در مجموعه داده ها دارند ، که هزینه مسلط O (N دارای مشاهدات × N^2) است - که منجر به زمان آموزش طولانی برای مجموعه داده های بزرگ می شود.
- بیش از حد: خطر بالاتر از بیش از حد در داده های آموزش و توضیح پیش بینی ها سخت تر است.
پس از انجام تنظیم هایپرپارامتر با استفاده از بهینه سازی بیزی ، ماتریس سردرگمی طبقه بندی کننده SVM و دقت مدل آن در زیر نشان داده شده است.

نمره SVM دوره زمانی مختلف: 0. 513 - 0. 639
در اینجا برخی از خروجی های مدل SVM آورده شده است.
y_pred:
- فروش: 19904
- هیچ چیز: 2345 ،
- خرید: 29
y_actual:
- فروش: 15551
- هیچ چیز: 773
- خرید: 5954
SVM بسیار بهتر از مدل LR عمل می کند ، که جای تعجب ندارد ، با این حال ، به دلیل افزایش اندازه مجموعه داده ها ، زمان آموزش ما به صورت نمایی افزایش می یابد و آزمایش پارامترهای مدل مختلف را بسیار غیر واقعی می کند. هر مدل بسته به نوع هسته حدود 4 تا 8 ساعت طول می کشد. با توجه به زمان طولانی آموزش ، ما تصمیم گرفتیم از یک شبکه عصبی برای افزایش بیشتر عملکرد و رسیدگی به مقدار زیادی از داده ها استفاده کنیم.
مدل فوق العاده پیشرفته: شبکه عصبی حافظه طولانی مدت کوتاه
در حالی که مدلها تا کنون برخی از دقت را به دست آورده اند ، آنها برای داده های سری زمانی بسیار ناکافی هستند. ما به مدلی احتیاج داشتیم که بتواند برای زمان و همچنین غیرخطی و اندازه داده های خود را در خود جای دهد. با توجه به این محدودیت ها ، ما تصمیم گرفتیم از یک شبکه عصبی حافظه کوتاه مدت (LSTM) استفاده کنیم.
این یک نسخه از یک شبکه عصبی مکرر (RNN) است که حالت های قبلی را به بخش فعلی تغذیه می کند ، بنابراین ماهیت زمانی داده های ما را در خود جای می دهد. یکی از نگرانی های اصلی در مورد RNN این است که ماتریس های وزن آن خیلی سریع از حالت به حالت دیگر تغییر می کنند ، بنابراین معنایی اساسی را فراتر از یک دوره خاص از دست می دهند. LSTM با اجرای یک "سلول حافظه دائمی" این کمبود را در خود جای داده است - ماتریس وزن آن از هر ماتریس لایه مستقل است.
سپس یک لایه ترک تحصیل را با استفاده از مقدار استاندارد 0. 2 اضافه کردیم تا بیش از حد از داده های آموزشی خود دلسرد شود. یک لایه ترک تحصیل قسمت مورد نظر نورون ها را به طور تصادفی ، در حین بازگردانی از بین می برد. به این نوع تقویت ، منظم سازی یا تجارت تعصب و تغییر نامیده می شود.
ما همچنین از تنظیم L1 در لایه LSTM خود استفاده کردیم ، که ماتریس های وزنی را به سمت 0 سوق می دهد و در نتیجه از بین بردن متغیرهای خاص. با توجه به اینکه بازارها رژیم های خود را در فواصل ناشناخته تغییر می دهند ، ما می خواستیم اطمینان حاصل کنیم که مدل ما می تواند یک مجموعه داده های آزمایشی را با شرایط کاملاً متفاوت اداره کند.
لایه نهایی ما یک لایه متراکم با یک عملکرد فعال سازی SoftMax بود. SoftMax یک بردار می گیرد و آن را به توزیع احتمال تبدیل می کند ، که به ما امکان می دهد احتمال جهت بعدی را تفسیر کنیم. ما سپس مدل را با آنتروپی متقاطع طبقه بندی کردیم ، که از دست دادن ورود به پیش بینی و خروجی واقعی اندازه گیری و به حداقل می رسد.
سپس آموزش مدل را شروع کردیم. پس از برخی تنظیمات ، ما یک مؤلفه مهم داده های خود را تحقق بخشیدیم. پیش بینی دقیق جهت (بالا یا پایین) مهمتر از پیش بینی این بود که قیمت بین دو دوره یکسان باقی بماند. بنابراین ، ما به وزن خود در کلاس های [فروش ، نگه داشتن ، خرید] به عنوان [1 ، 0. 2 ، 1] به پایان رسیدیم ، به این معنی که ما اهمیت پیش بینی دقیق نگهدارنده را به شدت کاهش دادیم. بهبود این وزن ، مقیاس آن با نوسانات کلاس دارایی است که معامله می شود.
وقتی صحبت از تنظیم مدل شد ، متوجه شدیم که از دست دادن اعتبار با زمان افزایش می یابد ، در حالی که دقت اعتبارسنجی کاهش یافته است. این نشانه داشتن یک مجموعه داده به اندازه کافی بزرگ است که یکی از مراحل بعدی پروژه ما است.
مدل ما در مجموعه داده های آموزش و اعتبار سنجی به سرعت (دوره های زیر 50) همگرا شد ، و این نتیجه گرفت که ما 74 ٪ دقت متوسط را در تعدادی از اجراها به دست آورد. ما می خواهیم توجه داشته باشیم که اگرچه این دقت زیاد است ، اما هنوز اقدامات زیادی وجود دارد که می توان از این جعبه سیاه به طور موثری در هنگام اجرای استفاده کرد.
کار آینده
- ویژگی های اضافی را ایجاد کرده و پارامترهای مدل را تنظیم کنید تا تأثیر عوامل اگزوژن را ضبط کرده و شهود مدل را توسعه دهید.
- ویژگی های نقدینگی را با مبادله از جمله تأثیر بودجه در مقابل تجزیه و تحلیل کامل الگوریتم های بودجه مبادله ارزیابی کنید.
- یک چارچوب چند مبادله را برای ضبط فرصت های احتمالی داوری ایجاد کنید.
- تفاوت های ظریف بهینه سازی از دست دادن در مقابل دقت را ارزیابی کنید.
- مدل های اضافی از جمله تجارت تأیید منفی ، حساسیت به بزرگی قیمت و مدلهای همبستگی متقابل بازار را بسازید.

ما را در سایت کتاب آموزش بورس دنبال می کنید
برچسب :
نویسنده : محمود استادمحمد
بازدید : 28
